The Definitive Guide to Clojure on the JVM
Want the best way to learn Clojure?
Invest in yourself with my Beginner Clojure Signature Course.
- 8 fundamental modules
- 240 fun lessons
- 42 hours of video
Clojure runs on the JVM and that is a huge asset to the Clojure language. In addition, Clojure was designed to be hosted. That means its semantics often defer to the underlying semantics of the host platform. All of that boils down to us needing to understand the Java ecosystem in order to get the most out of Clojure.
The Java ecosystem is big and it can be daunting. But fear not! You don't need to learn everything, and once you learn enough, it will be worth it. You will realize that it is not so intimidating. This guide will be your . . . guide.
This document is a work in progress. It is about 20% finished.
Table of Contents
- Understanding the abbreviations—JVM JRE JDK
- Which JDK should you choose?
- Javadocs
- Java Dependencies
- Leiningen and Dependencies
- Boot and depenencies
- Running Java with options
- The Java object model
More coming soon.
Understanding the abbreviations—JVM JRE JDK
We work on the Java Virtual Machine in Clojure, so it's important to understand all those acronyms that come up all the time. We will go through the different parts—the JVM, the JDK, and the JRE. It's actually super easy.
Here's a diagram of of how the three parts fit together.
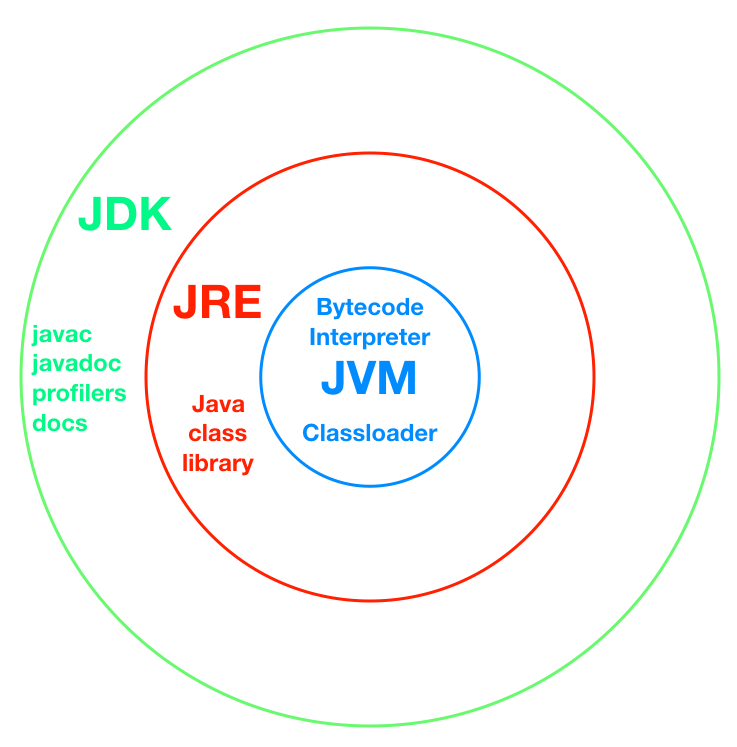
Java Virtual Machine—JVM
In the middle there's the Java Virtual Machine, which we call JVM for short. There are two parts to the JVM, which correspond to two main functions.
-
The classloader — finding and loading code
The classloader is what searches for class files. There is no actual spec for how those class files will be searched for, but each JVM is allowed to do it however it feels like it. There has been a de facto standard, which we'll go into when we're talking about where to put your class files and the classpath. But the JVM has to have some kind of classloader so that it can load in the class files, which is where compiled code is stored. -
Bytecode interpreter — executing code
Class files contain bytecode, which is executed by the JVM's bytecode interpreter. The JVM bytecode is a standard that works across many different CPU architectures. This is how the JVM achieves the write-once-run-anywhere feature. The bytecode abstracts away differences in platform, and the bytecode interpreter is what makes it run on your platform. There are therefore different JVMs for different platforms, including Intel, Arm, and embedded devices.
The bytecode interpreter is a really complex thing. That's where a lot of the research and innovations have come from. And usually the interpreter also comes with a Just-in-Time compiler (also known as JIT). The JIT will compile the bytecode into machine code as it's running. It has heuristics to determine when might be a good time to compile, and when it's better to wait.
The Java Virtual Machine was created by Sun Microsystems, but now it's owned and maintained by Oracle because Oracle bought Sun. So the JVM is an Oracle thing, though there are other implementations (usually forked from the main JVM). There's a spec and everything for how the JVM works and surprisingly, the JVM has stayed very stable. It's been a very good base for building on top of. For instance, the bytecodes are all backwards compatible and they've only added a few in like, 20 years. So it's a very stable platform.
Java Runtime Environment—JRE
The Java Runtime Enviroment (JRE) contains the JVM. It is
basically the JVM plus all the Java class libraries that
come with it. That includes all the standard libraries, all
the classes that are built into the language, the
java.lang package and subpackages, all of the external
things that might come with it, like you might have a JDBC
library included in your JRE.
What's included is just one more variable, obviously, because there is potential variation in what software comes along with it. Most desktops have the JRE Standard Edition which has the whole Java language, all the classes and everything that you need for running most software. You can find other JRE's that are tuned for embedded devices where there are severe space constraints.
Java Development Kit—JDK
Finally, there's the Java Development Kit (JDK). The JDK is the package for software developers. It contains the whole JRE, plus a bunch of development tools and documentation. Now most people won't need these on their machines. They will need the JRE. But they don't need a compiler and stuff, because most people aren't writing software.
The JDK has the development tools that we want, such as
javac, which is the Java compiler. The javadoc tool,
which will take Java source code and generate HTML
documentation. Profilers, stuff for hooking into the running
JVM to see what's going on, those kinds of development
tools. And documentation. Of course, there's probably other
stuff in there, but these are the main things that comprise
the JDK. When we develop Clojure, we usually want the JDK.
Which JDK should you use?
[Updated Feb 25, 2019]
The Java source code is open source. That means that anyone can download and build a JDK. However, there is a certification process called the Technology Compatibility Kit (TCK). Most companies will not have the resources to certify their own builds, so they will rely on one of the third-party JDKs that are certified.
However, there are many to choose from. They are essentially identical. The differences are 1.) licensing terms and 2.) support terms (in the form of security updates).
This is also complicated by a new release cycle. JDKs are now released every 6 months. As of this update, Java 11 is current. Java 8 is already not receiving updates. And Java 11 marks a major milestone: OpenJDK (the 100% open source JDK) has feature parity with Oracle's JDK (which has traditionally been 99% open source and 1% non-open source). You can now use OpenJDK builds with no issues.
We should go over the different JDK builds and how they differ in license and support.
Oracle JDK
Oracle releases a JDK which is available for free here.
The JDK is free to download and use for development, but production use requires a paid license. Paying for the license entitles you to long term support. That is, even after Java 12 comes out, Java 11 will still get support for years.
You probably do not want to pay for this as there are free alternatives.
If you want it, get the Oracle JDK here.
OpenJDK Build by Oracle
Oracle also releases a free, GPL build that has a "Classpath Exception" which makes it okay for business use. That is, your company's code is unencumbered by the terms of the GPL. These builds follow the release cycle. When Java 12 comes out, they will stop supporting Java 11 builds. You won't even be able to download Java 11 anymore. If you want security updates, you will have to upgrade to 12 quickly. Because of the 6-month release cycle, you will have to upgrade every six months.
If you can handle the frequent updates, this will be a good option.
If you want it, get the OpenJDK Build by Oracle here.
AdoptOpenJDK Build
AdoptOpenJDK is a community group that has banded together to provide builds, though they are uncertified, under the GPL with Classpath Exception (safe for commercial use to run JVM software). They have committed to release new builds (even of older versions) as long as there are security patches to the repos. Further, they will continue to support Java 11 for four years (you can issue bug reports and they will respond). That gives you a full year to upgrade to the next major version (which comes out three years after Java 11).
This is probably the best option for most people and companies.
If you want it, get the AdoptOpenJDK Build here. You can read more about what is included in support and what builds are available here.
They also provide JDK builds with an alternative JVM (called OpenJ9, originally create by IBM and what is part of Eclipse).
There are also some less popular options.
Red Hat OpenJDK Build
If you have a Red Hat Enterprise Linux license, that comes with Red Hat-built OpenJDK builds. These builds come with paid support.
If you already run Red Hat with the Enterprise Linux support, this will be your best option. Otherwise, it's not for you.
If you want it, get the Red Hat OpenJDK Build here.
Azul Zulu
Azul Systems makes alternative JVMs for better performance characteristics. They have a branded build called Zulu that includes paid support, even for minor versions such as 13 and 15. Some downloads are free, but the support is not and it is unclear how long they will be available.
Unless you are already working with Azul, this is probably not for you.
If you want it, get Azul Zulu here.
Amazon Corretto
Amazon is building OpenJDK now, too. It's fully GPL (with Classpath Exception), and it is fully certified through the TCK. They provide long-term support for free. It runs on Linux, Windows, macOS, and Docker. Another advantage is that it has been in production at AWS for a while, so is heavily tested.
You may want this if you are on AWS.
If you want it, get Amazon Corretto here.
Reference
The canonical guide to the new Oracle/OpenJDK licensing and support scheme is Java is Still Free.
Javadocs
So when Java came out in 1995, one of the cool things it had was a documentation system where you would put the docs right in the code and then there was a tool that would read-in your code and generate an HTML page. Back in 1995, automatically generated HTML pages for your docs was somewhat novel. The web was in its infancy.
Javadoc really helped improve the quality of the documentation. It standardized it. There's a lot of good information in the Javadocs. They document the classes available in Java libraries. And I would say they are the most common form of Java documentation. They are hyperlinked, so you can click on any class name and jump immediately to the docs for that class. Further, the docs show the inheritance hierarchy, including superclasses and interfaces, as well as subclasses.
Sometimes when you're dealing with a Java library, you just have to read the Javadocs. I've read so many, over so many years, that I know I've got tips and tricks for reading them efficiently. I've probably forgotten more than I can remember. But I'll share the big ones with you.
Tip: Know what version of Java you are running
There have many versions of Java and sometimes the standard library changes. Usually it grows, so there's new methods, there's new classes in the newer version of Java. They're pretty good about keeping the old APIs around. But it means that you're gonna have to figure out what version of Java you're running on to know what docs you should be reading.
The version of Java that you're running on is going to determine what methods you have available. Java is now on a 6-month release cycle, so it is very likely that if you haven't upgraded in a while, you're running an older version.
You can learn what version of Java you are running on your machine by executing this command:
java -version
Be careful because you cannot abbreviate to -v like you
might be used to.
That command will give you something like this:
openjdk version "11.0.1" 2018-10-16
OpenJDK Runtime Environment 18.9 (build 11.0.1+13)
OpenJDK 64-Bit Server VM 18.9 (build 11.0.1+13, mixed mode)
This is what it looks like for Java 11. It's typically the first line that tells you what version of the JRE you are running.
Tip: Be aware of the version of the Javadocs you are reading
The docs for all older versions are all online. However, Google and other search engines tend to favor older pages because they have accumulated more links. That means when you search for "java string" you will likely get older javadocs in the search results.
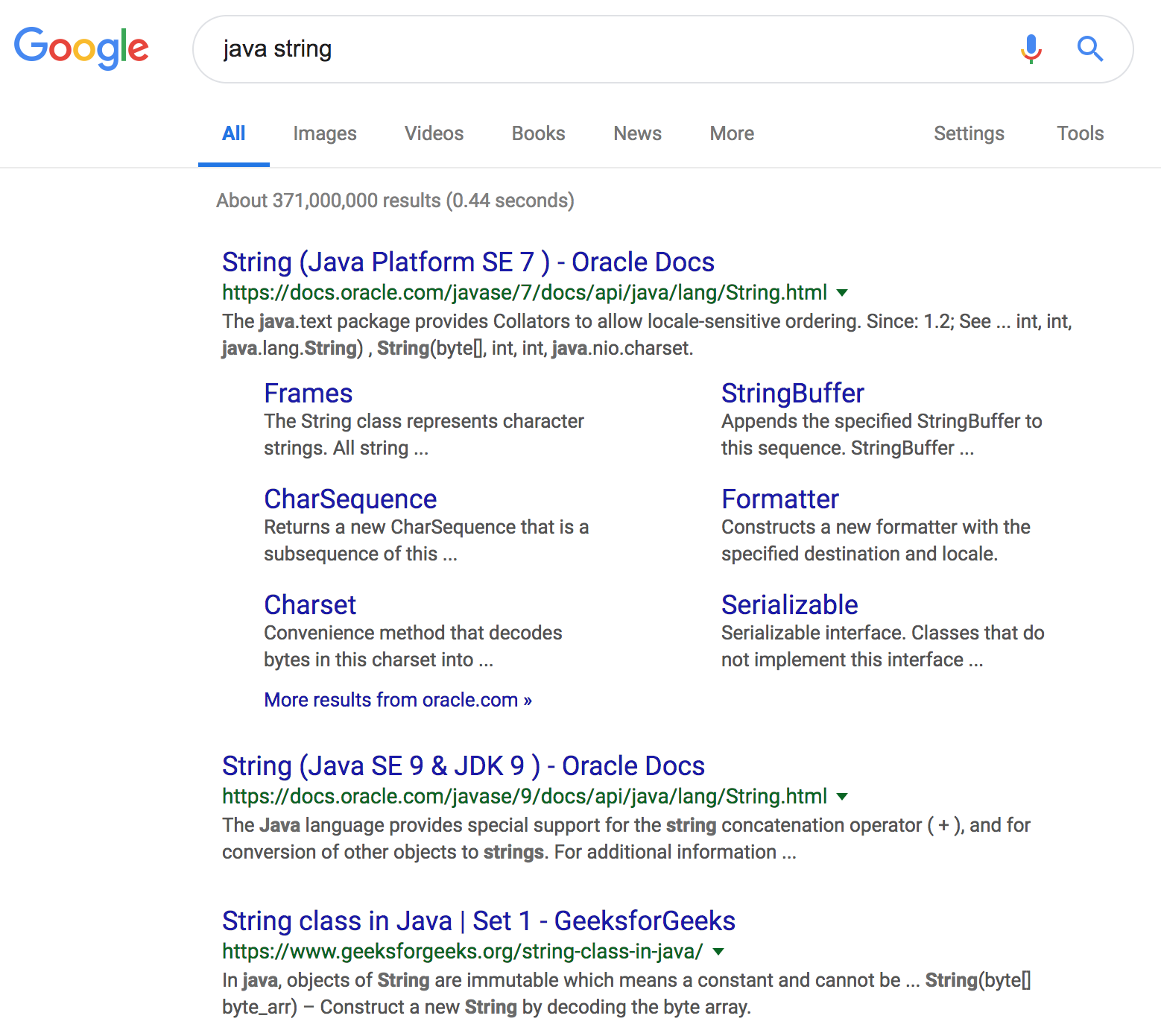
As I write this, the current version is Java 11. As you can see in the image above, a search for "java string" turns up the Java 7 Javadocs. The second result is the Java 9 Javadocs. These are the ones indexed by Google as the most relevant, because probably most people link to this one and Google is not smart enough yet to determine that really you should be showing Java 11.
My solution to the problem is to add the version number to the search string. Searching for "java 11 string" gives me the correct Javadoc as the #1 result.
Tip: Understand the structure of the Javadoc page
Let's look at this Javadoc for
java.lang.String
(that is, the String class).
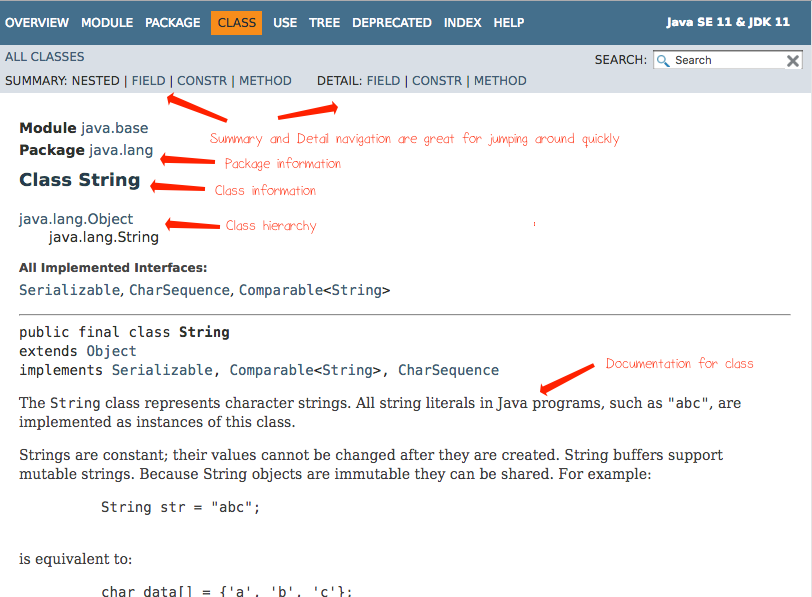
The first section of the document is a summary. More detailed information comes in the second section. I tend to use the summary section because I can get a higher-level overview of the class, then I click on a thing if I need more detail. The header contains useful navigation links to jump between the sections and subsections.
The top of each Javadoc contains information about the package, the name of the class, and the type hierarchy. Below that, there is the class documentation section, which is a human-written comment in the java source code. For the Java standard library, these tend to be pretty good documentation. Sometimes, for a third-party library, these will even be missing.
Tip: Use the summary tables to quickly find what you're looking for
Javadoc pages can get pretty big. You will want to use the summary section to quickly orient yourself, then use the links to get more detail.
The summary section includes a table containing all fields, a table for constructors, and a table for methods. The tables are succinct, with one-line descriptions. You can use them to find your way to more detail.
Also, in each of the tables, you can click on class names (for instance, the return type of a method). They are linked to the javadoc page for that class. It's a great way to understand the classes of a library.
Fields
Fields are not that common to use but they do come up. Here is the field table on the Java 11 String Javadocs. There is only one field, which is a Comparator that may be handy if you need it.
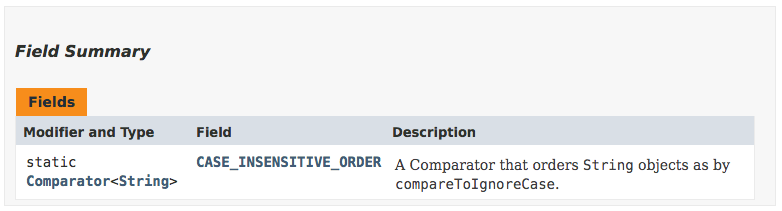
The table shows the type (with any modifiers), the name, and a one-line description. I can click on the name to go to the detailed view, which often has additional information.
Constructors
You will inevitably need to use constructors, which are used to create an instance of a class. Many Java classes have multiple constructors.

The same rule applies: use the summary table to find what you need and click the name to get more details.
Methods
Classes tend to have lots of methods. The method summary table has some nice filters at the top so that you can quickly find the types of methods you want.
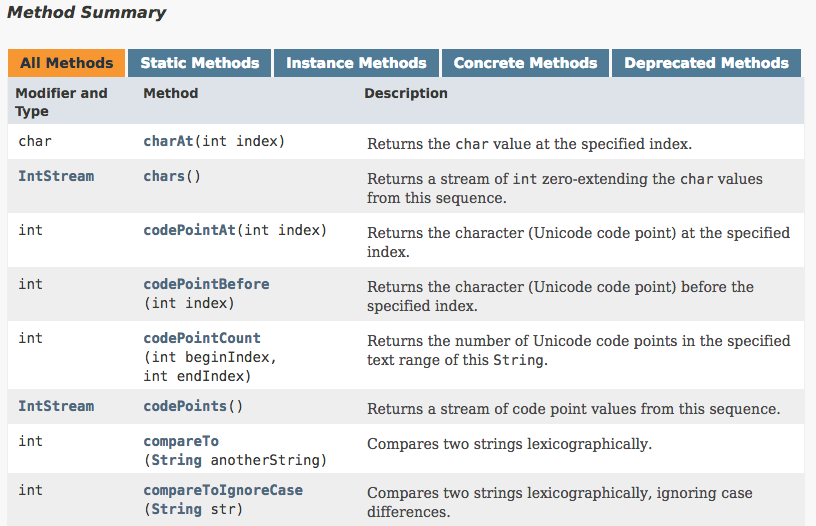
- Static methods are methods that do not require an instance of a class. They can work on just the Class itself. These tend to be general utilities.
- Instance methods are methods on the instance itself. They will have access to the object's state.
- Concrete methods are the normal methods (as opposed to abstract methods which don't have an implementation and need to be overridden).
- Abstract methods abstract methods can be part of an abstract classe. Abstract methods do not have an implementation, only a signature definition, and must be implemented by subclasses.
- Deprecated methods sometimes methods are marked as deprecated when you shouldn't use them anymore.
Note that the filtering options will only appear when there is at least one method of that option.
Again, if you want more detail, click the name to the detail section below.
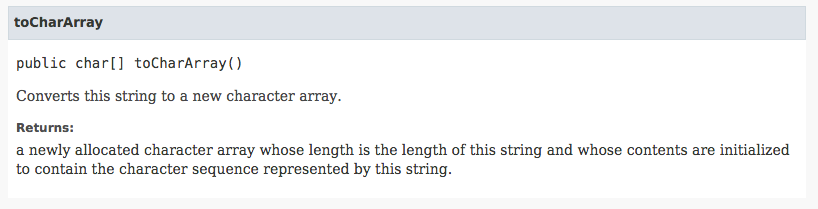
At the very bottom of the method summary table, you'll find a list of methods that are inherited from the superclasses, organized by superclass. These will only list the names, but you can click on them to jump to the specific javadoc page for them.
Tip: Use the package summary to get an overview of the available classes
If you click on the word PACKAGE in the top header bar, you'll come to the package summary page. It lists all of the classes, interfaces, and enums in the package. Of course, you can click on any class name to jump right to the page for that class. Java packages are a logical organizational unit in the Java language, roughly equivalent to Clojure namespaces. We'll learn more about packages later.

Tip: Use the module summary to understand available packages
If you click the word MODULE in the top header bar (or OVERVIEW if it's missing), you'll get to the module summary page. This page lists all of the packages that come with that module. In the case of the built-in modules of JRE and JDK, these are just an organizational unit to separate out different functionality. However, most libraries consist of a single module, so this will show all of the packages in that library.
Java Dependencies
Let's talk about dependency management on the JVM. We talked about how each JVM has it's own class loader, and that class loader has it's own way of figuring out where the class files are. It turns out that there is a de facto standard way that class loaders work. Let's go over that now.
When your code refers to a Java class, the class file, which contains the code for the class, must be loaded. The class file is searched for in what is called the classpath. That's a list of directories on your disk and Java Archive files (JAR files) to scan looking for the class file.
Java Archives—JAR files
Java Archive files are the unit of library distribution in
the Java world. They are zip files with the .jar
extension. A JAR file can contain many class files. When you
depend on a Java library, you typically will have it
packaged up into a JAR file, served by something like a
Maven repository.
JAR files can contain a number of things:
- a manifest which defines some options for the JAR
- class files (source code compiled to JVM bytecode)
- a resources directory containing other files you might need for the library (such as static assets)
- documentation (in the form of javadocs) may be included
- source code can be in the JAR as well
Note that documentation and source code tend to bloat the size of the JAR file, so they are typically not included in production builds of the JAR. Developer builds may have them.
Also note that it's also just a zip file, so there could be other things, like a README or a LICENSE file.
We'll go more into JAR files later. For now, just know that JAR files are the files that contain the code for libraries you depend on. In the Clojure world, we also use JAR files because they are convenient and let us tap into the existing facilities of the JVM.
The classpath
The class path is a list of directories and JAR files for all of the dependencies for your software. These days, we tend to let our project management systems handle the creation of these. It used to be that you would write them by hand.
If you'd like to see what a classpath looks like, you can have Leiningen or the Clojure CLI generate one for you.
Using Leiningen
$CMD lein classpath
Using clj
$CMD clj -Spath
It will look something like this. Notice directories and
.jar files separated by colons (:).
src:/Users/eric/.m2/repository/org/clojure/clojure/1.10.0/clojure-1.10.0.jar:/Users/eric/.m2/repository/org/clojure/spec.alpha/0.2.176/spec.alpha-0.2.176.jar:/Users/eric/.m2/repository/org/clojure/core.specs.alpha/0.2.44/core.specs.alpha-0.2.44.jar
You wouldn't want to write those by hand. Let the project
tool handle them for you. Notice the .m2/ directory, which
is where Maven stores a cache of JAR files it has
downloaded.
Maven
Maven refers to many things. Uttering its name can send shivers through many Java developers' spines. Speak softly when you mention Maven, and don't make sudden movements.
The scary thing with Maven—the thing developers are scarred by—is that it's a project build tool, configured with XML, that people lose hours of their lives trying to wrangle. Luckily, we rarely deal with that in pure Clojure projects.
Maven is also a repository protocol for JAR files. This is a great thing. Companies can run their own Maven repository, or use Maven Central, which hosts many public dependencies. The Clojure community has a Maven repository called Clojars, where many Clojure libraries are hosted. And there are even cloud-hosted private Maven repos, such as Deps. The best thing about it is that it's compatible with all of the tools. Leiningen, Boot, and the Clojure CLI all use Maven repositories.
Maven coordinates
Another good thing about Maven is that, as part of the protocol, there is a naming scheme for dependencies so that you can refer to a particular dependency by name and version. The name for a dependency is called its Maven coordinates. It consists of three parts:
- The group ID names the organization that produces the
JAR. This is typically the domain name in reverse order
(top-level first) such as
org.clojure. - The artifact ID names the library. Ex:
clojure. - The version string, which identifies a specific release
of the software. Ex:
1.10.0.
Some libraries are registered without a group ID, so the group is left blank.
See this guide to maven naming conventions for more information.
Because Maven uses XML, the Maven dependency is often listed like this:
<dependency>
<groupId>org.clojure</groupId>
<artifactId>clojure</artifactId>
<version>1.10.0</version>
</dependency>
Leiningen uses a much more compact form that includes the same three elements. Boot uses the same format.
[org.clojure/clojure "1.10.0"]
clj-time, the date and time library, does not have a group
ID, so the Maven coordinates look like this:
[clj-time "0.14.2"]
The Clojure CLI does it differently. Maven coordinates look like this:
org.clojure/clojure {:mvn/version "1.10.0"}
And clj-time:
clj-time {:mvn/version "0.14.2"}
Immutable artifacts
Typically, we want our artifacts to be immutable. That means that once we release the artifact to a public repository, it can never be changed. We want our builds to be stable—if we need to rebuild our web app, we want the same code in it as before. Maven Central and Clojars both enforce immutability of releases. Published artifacts never change and are available forever.
Snapshot releases
Sometimes, though, you need to publish an artifact somewhere so that it is available, but it's not an official, final release. That is, you're still working on it, but in order to test it, you need it in Maven. Snapshot releases let you do this.
If you put -SNAPSHOT at the end of your Maven version,
Maven will consider it to be a snapshot release and will not
enforce immutablity. Be careful when using other people's
snapshot releases in production because they can change.
POM files
When I make a library, you might depend on it. But my library has its own dependencies. These dependencies are listed in a POM file, which exists alongside the JAR file which contains the library. Using the POM file, your system can know all of the dependencies that my library has. Leiningen can generate POM files for you for your projects.
$CMD lein pom
Maven Central
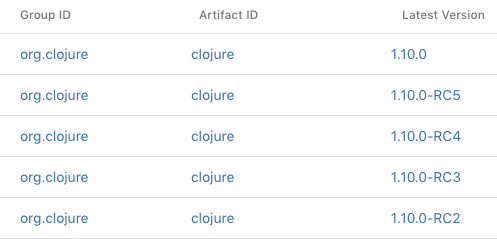
If you'd like to search for a dependency so that you can find out all of the available releases, you should use the Maven Central search engine.
Maven Central is a very usable, well-organized directory of groups, artifacts, and versions.
Clojars
Most Clojure libraries are hosted on Clojars, which is a community-run Clojure Maven repository.
Leiningen and Dependencies
Let's talk about how Leiningen manages dependencies. This is the project file that Leiningen requires this is actually one for an older project. It's got kind of like a weird structure that I've set up for it. It still works and I just wanted to show you some of the things in it.
Dependency basics
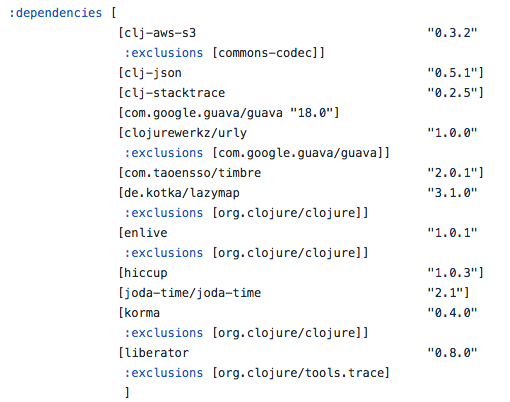
The dependencies in Leiningen go under the :dependencies
key. Usually we put the dependencies in a vector, though
there are other options. But vectors are what most people
use. Each dependency is itself a vector.
[org.clojure/data.csv "0.1.2"]
The vector contains a symbol first. The namespace of the symbol (the part before the slash) is the Maven group ID. It's optional. If you don't need one, you just leave it out, as in:
[hiccup "1.0.3"]
The name of the symbol (the part after the slash) is the Maven artifact ID. And the string is the Maven version.
Dependency directives
Leiningen dependency vectors can also contain directives that control aspects of the included dependency. These can give you fine-grained control over what dependencies are included in your project.
Exclusions
Let's say I want to use two libraries, clj-cat and
clj-dog. Both clj-cat and clj-dog depend on
clj-fur. However, clj-cat depends on clj-fur version
1.2 and clj-dog depends on clj-fur 1.5. This can lead to
a conflict and potential weird effects depending on what
order they are searched by the classloader. Basically, you
want to avoid having two versions of the same library on
your classpath.
To combat this, you can exclude certain transitive
dependencies with a directive. Let's say I want clj-fur
1.5 for some reason. That means I need to exclude clj-fur
1.2 in the clj-cat dependency.
[clj-cat "0.2.2" :exclusions [clj-fur]]
This will tell Leiningen to ignore the clj-fur dependency
from clj-cat. Since clj-dog also depends on clj-fur,
clj-fur will still be included in the classpath. But it
will be the version I chose.
It's hard to know what exclusions you want because when you include a library, most of the time you've got this huge tree of dependencies that you rely on. Every library depends on many other libraries. You've got the direct dependencies but also the transitive dependencies. The things that those dependencies depend on, and so on. You don't really know everything that you have to exclude but Leiningen has a feature that helps you out there.
If you run
$CMD lein deps :tree
You will get a listing of all of the dependencies in a
nested tree format. Here is a sample of the core.async
dependency and its transitive dependencies.
[org.clojure/core.async "0.3.443"]
[org.clojure/tools.analyzer.jvm "0.7.0"]
[org.clojure/core.memoize "0.5.9"]
[org.clojure/core.cache "0.6.5"]
[org.clojure/data.priority-map "0.0.7"]
[org.clojure/tools.analyzer "0.6.9"]
[org.clojure/tools.reader "1.0.0-beta4"]
[org.ow2.asm/asm-all "4.2"]
Now, if you scroll up to the top of the output of lein deps :tree, you'll see that there is a list of recommended
exclusions. I often pipe it to less so that I can scroll
through it easily.
$CMD lein deps :tree | less
Here is one suggestion:
Possibly confusing dependencies found:
[org.apache.httpcomponents/httpcore "4.4.1"]
overrides
[clj-http "2.2.0"] -> [org.apache.httpcomponents/httpmime "4.5.1" :exclusions [org.clojure/clojure]] -> [org.apache.httpcomponents/httpclient "4.5.1"] -> [org.apache.httpcomponents/httpcore "4.4.3"]
and
[clj-aws-s3 "0.3.2" :exclusions [commons-codec]] -> [com.amazonaws/aws-java-sdk "1.3.6"] -> [org.apache.httpcomponents/httpclient "[4.1,5.0)"] -> [org.apache.httpcomponents/httpcore "4.4.11"]
Consider using these exclusions:
[clj-http "2.2.0" :exclusions [org.apache.httpcomponents/httpcore]]
Notice that it shows that two versions of
org.apache.httpcomponents/httpcore are depended on, both
4.4.3 and 4.4.11. The last line suggests we add an exclusion
to clj-http.
Adding exclusions is all about ensuring a dependable, deterministic build.
Native Prefix
Sometimes, different jars are created for various platforms. For instance, there might be a Windows 10-specific build and a macOS-specific build.
[native-library "1.22.1" :native-prefix "macos"]
Classifier
An uncommon part of the Maven coordinates is the classifier. Sometimes, people build the same library for different purposes, each named by a classifier. If you need to, you can add that to the dependency.
[library "4.44.2" :classifier "jdk11"]
Tip: Find old dependencies with newer versions available
Libraries are constantly being updated, and sometimes you want to stay current.
With Leiningen
There's a Leiningen plugin called
lein-ancient. It
will tell you the libraries that have older versions.
After installing it, you can run it.
$CMD lein ancient
Here's a short excerpt of the output on one of my older projects.
[clj-aws-s3 "0.3.10"] is available but we use "0.3.2"
[clj-json "0.5.3"] is available but we use "0.5.1"
[clj-stacktrace "0.2.8"] is available but we use "0.2.5"
[com.google.guava/guava "23.0"] is available but we use "18.0"
[com.taoensso/timbre "4.10.0"] is available but we use "2.0.1"
[de.kotka/lazymap "3.1.1"] is available but we use "3.1.0"
With Clojure CLI
There is a project called
Depot that will tell you
updatable versions in your deps.edn file.
You can use it without any installation.
$CMD clj -Sdeps '{:deps {olical/depot {:mvn/version "1.7.0"}}}' -m depot.outdated.main
If you do install it, it's more convenient to run like this:
$CMD clj -Aoutdated -a outdated
Both versions give you output like this:
| Dependency | Current | Latest |
|---------------------------------------------------+---------+--------|
| com.google.api-client/google-api-client | 1.23.0 | 1.28.0 |
| com.google.oauth-client/google-oauth-client-jetty | 1.20.0 | 1.28.0 |
| org.apache.xmlgraphics/batik-codec | 1.10 | 1.11 |
| org.apache.xmlgraphics/batik-dom | 1.10 | 1.11 |
| org.apache.xmlgraphics/batik-transcoder | 1.10 | 1.11 |
Boot and Dependencies
Now we need to talk about dependencies with
Boot. Managing dependencies with
Boot is very similar to Leiningen but it has some
differences. So as you may know, with Boot, the dependencies
can be loaded at runtime, so there is no separate project
file that describes all the options for the project. You can
just add dependencies using the set-env
command.
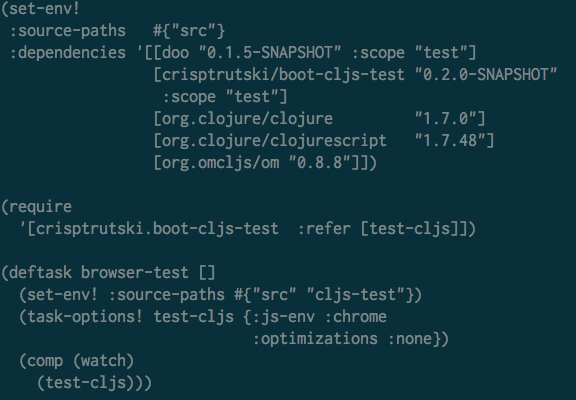
Most Boot projects have a build.boot file. And that's what
describes all the Boot tasks that you wanna be able to
run. So this one has some dependencies and you notice that
they look very much like Leiningen dependencies. They've got
the same structure, using a symbol with a name space and a
name. They've got the version number in a version string. In
this example you see a :scope directive, which can be done
in Leiningen, too.
[crisptrutski/boot-cljs-test "0.2.0-SNAPSHOT"
:scope "test"]
Underneath, both Boot and Leiningen use the same library, which is called Pomegranate, for dealing with dependencies.
Tip: List your Boot dependencies
If you want to list the dependencies in your project without running it, you can run a single command.
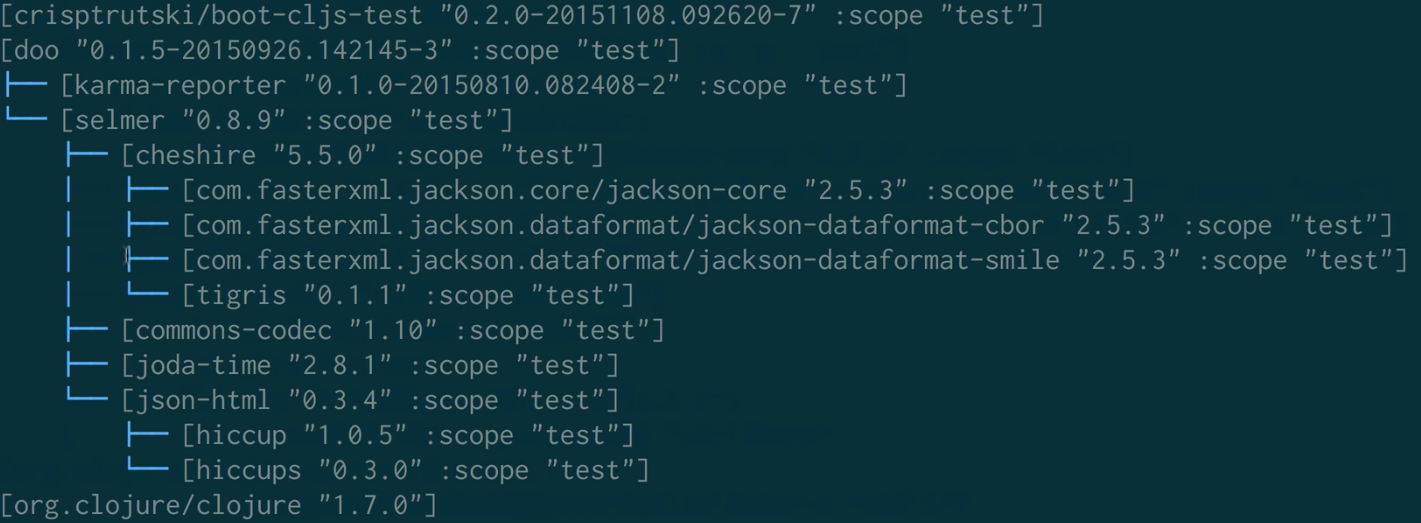
$CMD boot show -d
We see a tree of all of our dependencies.
Tip: Show dependency conflicts
If you want to see the dependency conflicts, that is, multiple versions of the same library being included, we can do that, too.
$CMD boot show -p
This shows a nicely formatted view of conflicts and how they have been or should be resolved.
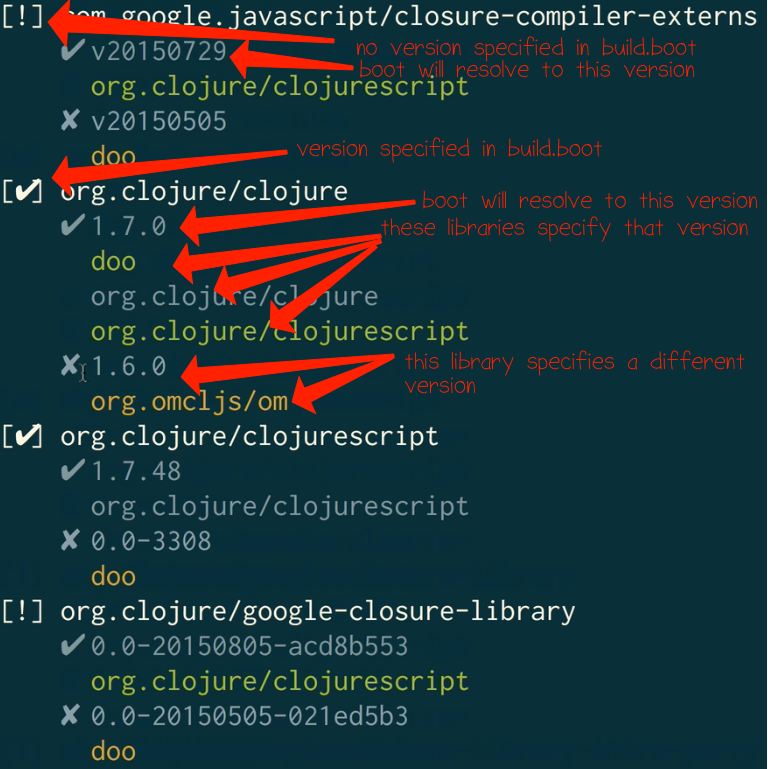
Checkmarks in brackets [u2714] indicate that no action is
needed. You are explicitly setting the version directly in
your dependencies. Boot will select the one you
specified. However, it is showing it because other libraries
depend on a different version. That is potentially a
conflict.
Exclamation points in brackets [!] indicate that you are not
setting a version directly and there is a conflict. That
means two libraries specify different versions that they
depend on, and there is no way to resolve them.
Nested underneath each library, we can see which version Boot will select, along with which library specifies each version. Boot puts a checkmark next to the version it will select.
Running Java with options
When you run a Java program, you start up a JVM. You do that
with the java command, which comes with the JRE. It's what
starts the JVM, loads up a JAR file, loads up classpath, and
executes.
Tip: The java command line argument conventions are different from Unix
The Unix standard for command line arguments makes a
1distinction between abbreviated and full-length command line
arguments. You use - for abbreviated and — for
full-length args. Here's an example where I'm searching for
"conj" in Clojure files.
$CMD grep —line-number conj *.clj
I'm using the full-length command line argument
—line-number. This is equivalent to:
$CMD grep -n conj *.clj
This last one uses the abbreviated version of the same
argument -n. This is convenient because abbreviated args
can be smushed together like so:
$CMD grep -nvi conj *.clj
This actually has three args: -n prints line numbers, -v
inverts the match (shows lines without matches), and -i
makes it case-insensitive.
I can get really used to that style of command line argument
and get confused and frustrated when java does not follow
it. I don't want that to happen to you.
Java's command line argument convention is simpler and less
convenient. All command line args take a single -, and
there's no short/long form. There's just one long form, and
sometimes it's just some letters that don't spell out
words. You just have to look them up.
Let's look at some examples:
To print out the current version of java you have:
$CMD java -version
Notice the single hyphen and the long word. It's so common to abbreviate that in commands, I'll sometimes type:
$CMD java -v
And wonder what's going on. You just have to spell it out.
And sometimes I'll type java —version and that doesn't
work either. Muscle memory is fighting against me. I just
need to remember that java is different.
Some options look like this:
$CMD java -cp tools.nrepl-0.2.12.jar:clojure-complete-0.2.4.jar
Notice the -cp. That's not two short options. That's just
one option. I get confused on that sometimes, too.
And some options look like this:
$CMD java -Xmx4g
That's one option, which sets the maximum heap size to 4
gigabytes. Let's break it down. The capital X specifies
that it's a nonstandard option. The mx specifies the
option name, and the 4g is like a parameter, which means 4
gigabytes.
Tip: Run java with no arguments for a list of options
The options your JVM come with are listed with brief descriptions. There's a lot, soq you probably want to pipe it to less. That is,
$CMD java | less
Tip: Know what version of Java you are using
You can learn the version of Java you are using with the following command:
$CMD java -version
Although Java is typically very stable and backward compatible, occasionally there will be breaking changes. There was some major incompatibility between Java 8 and Java 9, for instance. Plus, many times you'll need to look up specific options that are available for a particular version. It's just good to know in general.
Tip: Use java -jar for executable JAR files
Some JAR files are executable. That is, they are
self-contained (they contain all code they will need to run,
including libraries) and they have a class specified in the
Manifest that tells the JVM what class to run main() on.
In this simple example MANIFEST.MF file, we are telling Java
to run JarMain.main() when the JAR file is executed.
Manifest-Version: 1.0
Main-Class: JarMain
You cannot execute a JAR and use a classpath at the same time.
Running an executable JAR is not typical. Usually, we are going to set the classpath. When Java loads up and you start running some code, it has to search for what are called class files, which are the compiled bit code version of your Java source code. Each class file corresponsds to one class. Inner classes will get their own files, too, and they're named with the dollar sign, which we'll get to in more detail later.
So we've got a classpath, and so we specify it like you would specify your executable path in Unix. You put directories and JAR files with colons. And those directories have to point to a directory containing the package hierarchy with class files in it. That's if you've got class files directly on your disk.
Usually you're not going to be dealing with class files on your disk like that anymore. Usually you have many JARs, corresponding to libraries, that you put on your classpath. A JAR file is a collection of class files in a zip. It's all zipped up into one big package, and the Java VM can read it.
There's a thing called a main() method on certain classes,
and it's a static method, but it's an entry point into your
program. It's a method that the JVM can find to start
running. If a class has a main() method, we call it a
main class.
Clojure has a main class, called clojure.main. Here's how
I can run it.
First, I have to add the Clojure JAR to the classpath. I do
that with the -cp option. I happen to have the Clojure
1.8.0 JAR right in my current directory. Otherwise, you
could use a path to it. I could also add other JARs by
separating the paths with colons.
Second, I specify the main class I would like to run. In
this case, it's clojure.main, which will launch a REPL.
$CMD java -cp clojure-1.8.0.jar clojure.main
Java takes other options as well. Let's say we wanted to
change the heap size. When Java starts up, it will grab a
bunch of memory for the heap. The amount it grabs is the
minimum memory option. Then, as it needs more, it will keep
asking for more, up to the maximum. We will see these
options in more detail later. For now, I just want to show
where the options go in the java command.
Let's say we want to run the same main class, but with a
minimum heap size of 1 gigabyte. The option is named -Xms,
followed by the size. We need to put that before the main
class in the command.
$CMD java -cp clojure-1.8.0.jar -Xms1g clojure.main
We can also specify the maximum heap size with -Xmx.
$CMD java -cp clojure-1.8.0.jar -Xms1g -Xmx2g clojure.main
Valid heap sizes have to follow these rules:
- End in
k,m, orgfor kilobyte, megabyte, or gigabyte. Capitals (K,M,G) are okay. - Maximum size of the heap is
2g. - Whole numbers only. No decimals.
1.5gis not allowed.
To set the stack size, you can do it like this:
$CMD java -cp clojure-1.8.0.jar -Xss4m clojure.main
That will allocate 4MB for the stack.
Setting JVM options with the Clojure CLI
The Clojure CLI lets you pass in JVM options directly on the command line, like so:
$CMD clj -J-Xmx512m
Just prefix the option with a -J and no space.
Setting JVM options with deps.edn
You can set JVM options within your deps.edn file to have
them set for the project. These are used whenever you run
the clj command within that directory with the specific
alias.
So let's say you wanted to large-memory version of your
project. You could set up a :large-memory alias in your
deps.edn file, like so:
{:deps {...}
:aliases {:large-memory {:jvm-opts ["-Xms8G" "-Xmx8G"]}}}
Then you can apply the alias like this:
$CMD clj -O:large-memory
Setting JVM options with Leiningen
You can add JVM options to the Leiningen project file.
(defproject ...
:jvm-opts ["-Xms8g" "-Xmx8g"] ...)
They can even go in your ~/.lein/profiles.clj in your
:user profile.
Setting JVM options with Boot
You can include JVM options in Boot with the
BOOT_JVM_OPTIONS environment variable:
export BOOT_JVM_OPTIONS='-Xmx2g -client'
Otherwise, you can also set it in the boot.properties
file:
BOOT_JVM_OPTIONS=-Xmx2g -client
Boot will check the local directory first, then the
~/.boot/boot.properties file.
The Java object model: Fields, Methods, and Constructors
Java objects have fields and methods. Fields are state held inside the object, and methods are like functions that are run within the scope of that object. Methods can read and write the state of the object they are in.
In Java, objects are created with constructors, which are
special methods that are invoked using the new operator.
Methods are the primary way we access functionality in Java. Secondarily, we will also need to read and write to fields. Finally, we'll need a way to construct objects. These are the three main ways we interoperate with Java from Clojure.
Methods
In Java, if I wanted to call the toString() method on an
object, I could do so like this:
obj.toString()
In Clojure, I can call the same method like this:
(.toString obj)
That is, in what is normally the function position (the
first element after the opening paren), we put a symbol
starting with a .. That dot tells the Clojure compiler
that it should consider that a method call. The first thing
after the method call is the receiver of the method. Notice
that in Java, the reciever comes before the method name, but
in Clojure, it looks like one of the arguments.
When the method has arguments, we put them after the receiver in Clojure. So check out this Java code:
myString.indexOf("hello")
In Clojure, that turns into:
(.indexOf myString "hello")
Classes have methods as well. These are called static methods. They don't have access to the state of any particular object. Instead, they are called within the scope of the class (which can have state itself).
In Java, you can invoke a static method by naming the class, then using the standard dot notation:
Character.isWhitespace(c)
This calls the static method isWhitespace() on the class
Character.
In Clojure, this same method call looks like this:
(Character/isWhitespace c)
If you look closely, this too is a symbol, this time with a
namespace. The name of the class is the namespace, and the
name of the static method is the name of the symbol. No
extra this argument is required as is required for
instance methods.
Fields
Each object has zero or more fields, which are like variables inside of the object's scope. Each instance of a class can have different values of fields. Collectively, the fields make up the state of the object.
Fields are access in Clojure in a similar manner to
methods. So you can access the x property of an object
like this:
(.x obj)
However, what if the object has both an x() method (with
zero arguments) and an x property? Which one are you
referring to? Clojure prefers the method call. That is, if
there are both a zero-argument method and a field by that
name, Clojure will choose the method.
If you want to refer only to the field, you should add a hyphen before the name of the field, like so:
(.-x obj)
That will only look for a field named x. Because it is
specific to fields, and also because this is required in
ClojureScript, this is the preferred way to refer to fields.
Constructors
Constructors are like methods that build a new instance of a
class. Although there is a default constructor if you don't
define one, the intent of the constructor is to initialize
the state of the object before it is accessed. In Java, you
use the new keyword to invoke the
constructor. Constructors can take parameters to initialize
the object to the desired state.
For example, you can instantiate a
java.io.BufferedReader
like so:
BufferedReader br = new BufferedReader(fileReader);
In the code above, the fileReader is passed as a parameter
to the constructor. The new keyword indicates that it is a
constructor.
In Clojure, we can also call constructors. We use the
post-. syntax. To replicate the Java code above in
Clojure:
(def br (BufferedReader. file-reader))
To call a constructor in Clojure, we put the class name,
followed by a ., in the function position. The number and
types of arguments will determine which constructor is
called.
Want the best way to learn Clojure?
Invest in yourself with my Beginner Clojure Signature Course.
- 8 fundamental modules
- 240 fun lessons
- 42 hours of video