Testing Stateful and Concurrent Systems Using test.check
Generative testing is great for testing pure functions, but it is also used to test the behavior of stateful systems that change over time. Those systems are often designed for highly concurrent usage, such as queues, databases, and storage. And then sometimes your code is also asynchronous, such as in JavaScript. Learn several patterns to find inconsistencies across platforms, race conditions, and corner cases. This talk assumes basic understanding of generative testing.
Slides
Transcript
[Hi. What's happening in our industry would have been unthinkable ten years ][ago. more people than ever---an amazing number of people---are happily employed writing lisp and doing functional programming. i think that's awesome. ]
[More people than ever are asking "how do I develop a functional mindset?" And generative testing is a really good answer to that question. There's nothing like generative testing for forcing you to think about the properties of your system as a whole. And there's nothing like generative testing for honing functional thinking. And I am honored and privileged to teach it to you today. ]
[The title of this talk is Testing Stateful, Concurrent, and Async Systems using test.check. My name is Eric Normand. I run a company called PurelyFunctional.tv. There's a newsletter. It's free. You should sign up! It's meant to inspire Clojure programmers. It's weekly. It's about ten links every week.]

[ So, a map of the talk. First, we're going to develop a few example-based tests that we can then pick on as a strawman. Then we're going to use those same tests but rewrite them generating the data instead of hard-coding the data. Then we're going to develop tests that test a sequential—basically, generate the whole test. And then we're going to add parallelism to this so we can test for race conditions.]
[A show of hands. Who tests their system? Okay, that's just about everybody. A few people weren't paying attention. Who uses generative testing? ][alright, maybe a half of you. okay, cool! well, i hope that the half of you that don't use it start to use it by the end, and the half of you that do use it learn some new techniques for doing this. ]

[Alright, so let's start with the system that we're testing. It's a very simple system because I only have 40 minutes. It's just a key-value database. This database might be on another server and you're sending messages over the network. It could be on the same server using like RPC or something. And then it also could be in-memory. It doesn't matter. ]
[What's important is the interface. ][it has these operations. you can create a new one empty. then you can clear it. that just gets rid of all data in it. you could store a key-value, delete a key, fetch a key and get the value out, and then ask for the size. okay, so there are five operations. pretty simple. does what you expect.]

[So let's write some tests using clojure.test. We can define a test called store-contains. We want to store a key and see if the database will fetch it back out for us. Pretty simple test so we created a database. Create a key and a value. Store it. Fetch it out. And then assert that it's equal to the value that we expect.]

[Another test. This one is that the second store is going to overwrite the value for the first store. So we create a key and two values. Store them both in order. And then when we fetch it out we expect it to be equal to the second value. Make sense?]
![]()
[Okay, clear-empty. After I clear, there shouldn't be anything in it. So I'm going to store something in it just to make sure that I do actually clear something. Then I'm going to clear. Check the size should be zero. ]
I don't want you to feel bad about these tests. I write tests like this too but you should feel bad about these tests. And I know when I say feel bad with testing, there's a lot of shaming going on with TDD. And like whether you're a real programmer if you don't do TDD. And that's not what I mean. I don't mean you should feel guilty. I mean you should just be scared. These tests are not doing very much. They're testing a very little bit of your system. Just to put this in perspective, you might think well it's a very simple system. There are only five operations possible and like it's not that critical. Right?
[ ]
]
[Let's compare it to a system like this. This is the cockpit of an airplane. A lot of switches and dials and gears and legs and you know, other things you can do. And what if I wrote tests as I did for the key-value database but for this?]
[ So I say I'm going to press this button and then flip that switch. I'm going to test it. It did the right thing. Okay, now I'm going to flip this switch and turn this knob and tested. It did the right thing and then I'm going to turn to move this lever and put that switch and test if it does the right thing.]
[Would you fly on this airplane? If those were the only tests that I ran right? And so this system looks complicated. It looks big. There's a lot of possibilities here and it's a very dangerous critical system. But what is the size of our system this database that we're writing? Let's just ask a few questions and think about it.]

[So how many strings are there? But if my keys and values are strings, that's a lot of different inputs that are possible. Infinity. How many unicode characters are there? Thousands. How many key-value pairs are there? A lot. Infinity. How many operations are there? Five. How many pairs of operations? Actually 25. Five squared. How many triples of operations? 125. And I mean it goes up from there right?]
[ So this is actually a really big system. But what is different is, compared to the cockpit, is that the description is small right? It's only five operations and you can kind of explain it in a few sentences. ][so we want to be able to capture that small description in our test---which we haven't done if we just write all the examples. so i've had three tests. you could expand that out. 225 doing the pairs of operations. still, you wouldn't come close to testing the whole description.]

[Alright, so let's get into generative testing. The first][ idea you have to know is generator. generators are objects that generate random data of a given type. so the data we need are keys and values and we'll just say their strings. so this is saying keys are random strings and values of random strings.]
[W][e can sample our generator and get 20 values out into what it looks like. this is just random. you run it again, you'll get different stuff but you noticed already. we've got way more interesting data than our dinky string with a character in it. we got an empty string that's really interesting.]
[Usually, a][ good corner case we've got some characters that i don't even know what they're called or how to type them. you got this like over score one over here kind of like that one divide sign that's nice. anyway, there's much more interesting rich data here. ]
[Okay. Now we're going to set up properties which are kind of like saying we can translate our tests. Our original tests into properties. Properties are just assertion on our system.]

[We're using the defspec which hooks into the clojure.test. Test runner store contains the name of our test and we're going to run a hundred tests or didn't generate a hundred different types of this. So we're using a ][prop for all macro. and what this is basically saying is select a key from that generator and a value from that generator. create the database store. the key-in value and then fetch it out and compare it to the right. saying it's basically the same code as before. and notice it returns a boolean that it returns false and the test fails, you don't have to use the macro.]

[Alright! Next test is to overwrite this one. We're going to set a K and two Vs. Store them both and then we fetch it out and compare. It should be equal to v2 same code. ]
![]()
[This one I'm not going to go through line by line but we're storing the random K,V and then fetching ID and clearing it and checking the size. Alright, what is a failure look like?]

[ Failure. You'll get a map that reports what happens if we find a failing case. It's got Kiev results false because we returned false when they eat. When they're not equals. Store contains is the name of the var that's interesting. Failing signs? There's a bunch of stuff in here that I don't really use that much. ]
[I'm not going to go over it but this is the K and V that were generated for this failing test case. Notice it's a really long crazy string that failed. I don't know what to do with that. I can't debug that. Why did that fail? I don't know. But luckily, what test check does is it will shrink it for us. And what shrinking means is it takes that string. Say this K and it removed the character from it and sees and reruns and says does it still fail. Okay. And if it does, then it removes another character and then runs the test again. And sees does it still fail and it keeps doing this until it can't find any ]
[Another thing that we'll do besides just removing characters is it will decrements the character code and try that string. And so it keeps doing that keep doing that until it won't fail anymore. And then it returns the smallest one. That still failed and notice how small it is. So with this, I can go in and debug and it turns out that there's a bug with that Ashe character.]
[That was a special character and my code went through a code path that checked for that and crashed. And it gives you the feed so you can rerun the same test. I just checked the test bar. Figure out which one failed. And then the smallest to see if I can reproduce it. You can also take this smallest and turn it into an example based test so you don't have a regression on that test.]
[Okay. But the thing is, we could sit there and write 25 tests like this generating random data. But we're still not capturing the description of the system that I was talking about. That really small description. What we want to be able to do is describe the entire behavior and test it in one go.]

[Okay. So how do we do that? It's actually quite easy. First, there are four steps. Okay. The first step is we're going to build a model of our system. It turns out that a key-value database---the properties that we're interested in. Is the same properties that HashMap has. Alright. Keep all your database stores keys and values hashing. Have source keys and values same overwrite properties, same clearing property, everything's the same.]

[Okay. Step two. We're going to take the operations and reapply them and what we want to do is run these operations on our database. Run them on a HashMap and then at the end, compare that they're equivalent. That we got the same answer. So we're going to make generators for all of our operations or turning them into data. We're using the gen/return generator which just always returns a constant value and so we're returning a tuple. That starts with the keyword clear with the same thing with size. It's just a constant tuple with the size because there's no parameters.][ so we just need to generate it.]
[Next thing is we have store. Store has two parameters so we're making a tuple that starts with the keyword store and has a random key and value in it. Same with delete except we just need the key and then fetch tuple with the constant keyword. fetch and a key. Then we can make a generator that generates a vector of these and we use the one of generator which chooses a generator from this collection. And then chooses a random value from that generator.]

[ So in the end, we're going to get a vector of operations. Let's sample it to see what it looks like so we could have the empty vector. So no operation. We see one with clear another empty one. We see one with a fetch and a clear or clear a fetch. A clear fetch and a side. So we're getting some really weird tests. We would never write these tests but that's interesting right? We didn't have to write them. They're just generated for us automatically.]

[Alright. Now we need to make the runner to run these operations on the database and then once run them on the HashMap. Let's start with the database. Take a database and a vector of operations. We're going to iterate through these operations we're destructuring. So we're getting the name of the operation and the key and value if they exist. We're going to dispatch on the name. It's a clear. We're going to call clear. If it's size we call size and they're all the same right? ]

[We're just calling the corresponding function. For our HashMap runner because it's an immutable value. We're going to use reduce. So notice where our initial value is. The database that we're getting it's a HashMap but we're calling in the database. And we're reducing over the operations. You're going to destructor it same thing but this time I have to say we're only interested in the mutation properties of these operations right? So we're going to compare them at the end. We don't care if intermediate fetches are giving us the right value. We could care but in this example we're not okay.]
[Alright. So clear. Just sets it to the empty map size does not mutate. So we just returned the HashMap we got. Store is like a socially disliked dystocia and fetch doesn't modify it. So we're just going to return the HashMap.]

Alright. Now we can define a property. We're calling it hash-map-equiv. We're going to generate a sequence of operations. We're going to run our ops on our HashMap and create a refresh database. Then run our ops on the database and then compare them that they're equivalent.
[We don't have that function defined so let's define it a quiz. What does that look like? Take the database in the HashMap first. It compares the size of the HasMap to the size of the database. Make sure they're equal. And then it's going to go through every key-value in the HasMap and make sure that the equivalent can value are in the database.]

Okay. There's a problem with this though. I'm developing this incrementally. I'm writing the naive code and then making it better each time. The problem is, when we're generating keys, we're generating random keys each time we generate keys. So it's a bit like we have this set and we have a store and each one is getting a random key. It's a bit like I asked 10 of you in the audience to choose a random star in the galaxy and expecting that some of you would choose the same star right? We want to test that. If I do a store and then I do a fetch, or I do a store and a delete with the same key that there's some collision right? We're not testing that. They're the same teeka sort of very unlikely to choose the same key.

{kind=link}
[ So what do we need to do? What we could do is I could choose a solar system in the galaxy. And then ask you now the 10 of you choose a planet out of that solar system. And because the solar system is really small, I can guarantee you well there's a higher probability of having key collisions. Alright. So we want to still possibility that there are no collisions but it's much higher probability that there are. ]

[So we want to encourage these key collisions. How do we do that? Really easy trick. So these are the same. It's just the same generators. There's no parameters. But here with store, we have keys we're changing it from a generator to a function that returns a generator. So this function takes the set of keys. It's like we're passing in the solar system to choose from. We generate a tuple and notice the keys here is selecting a random element from that keys collection.]
[We do the same trick with delete. We are selecting a random element from the keys collection that we pass in. Same thing with fetch. Now we have this helper function that takes the keys. It generates this vector and notice we're passing the same keys that we get an argument to the individual functions. So all of these are going to be selecting from a small set of keys.]
[It encourages collisions. And then we just here's where we generate our solar system our small set of keys. The non empty vector of keys and then we pass it to gen-op star. And that will give us a sequence of operations with a good number of key collisions. ]

[We can sample now. These won't have collisions because they don't have two operations with keys. But this one has a collision notice. Whether you loved twice, this one has a collision. So I just wanted to double check that I'm getting some collisions in there. So I get curious about like what am I actually testing. How big is this system that I've got? So just using the repple I've made this query. Like how big is it if I generate a hundred sequences of operations? What's the biggest one? How big am I getting here?]
[It turns out I got 91 when I generated 100 random samples of op-sequences. The biggest one was 91 long. What about if I do a thousand? I got 96. So I think there's some like diminishing returns to the size of what you're doing. I know there's a normal curve here and you get out further and further. You're just getting like these smaller and smaller outliers.]
[But just out of curiosity. If I have five operations, ninety one long. How big is that system? Four times ten to the 63. There's a really big system and I'm only generating a hundred out of that. So it's not like I'm covering the whole system here. But what is interesting is when you get something that long, you do have a lot of those pairwise interactions, triple wise interactions going on. Ninety one operations. You're getting some interesting interactions going on.]

[Oh what does the failure look like now? We rerun our test with these new generators. Here is a failure. This is the operation sequence that we ran. It's actually 49 long. This one crashed or broke then in detail to meet our expectations. But look at the smallest. Look at the shrunk size like that.]
[I can actually go in and debug. I can look. I'll look store broke when I passed it this string. And in fact, that is the exact bug that I introduced. So it's really easy to debug. Okay. So we're able to describe our system. We're basically saying it's like a HashMap. Very short description but we live in a multi-core world. This thing is going to be accessed in the network. ]
[ ]
]
[What about race conditions? How can we test for those? Generative testing can do it! So what we need to do is make a runner that runs in a new thread. So the top function here just starts a new thread and it calls DB run. ]
[Alright. So it's just running our thing in a new thread. And then we can have a vector op-sequences. And we just run bang our running thread over all that for every op-sequencse in there. We're making a new thread and running them all. But it's more complicated than that because we don't know when the threads are going to finish. So we can't just compare them equivalent until all the threads are done. ]

[So we need to do this trick where each thread creates a promise and then after it finishesits DB run, it will deliver on that promise. And we return the promise from the function. So then when we do our thread run, we have to remember that thing. So we're doing a map. Map is lazy so we have to do run it to start all the threads. And then we're going to run bang deref on it which is going to block until all the promises are done.]

[Okay. There's another problem. Because if we have a lot of sequences, it could be that we start the first thread and it finishes before we even get to the end of the list and start the last thread. We want them all to start at the same time. So there's another trick it's called a latch. ]
[Like a latch. Say it'sgoing to release the gate. That all the horses start at the same time right? You want all those racehorses to have the same chance of winning. So we passing the latch up at the top and then right after we start our thread.]
[The first thing we do is we blow on the latch. Okay. So when we do thread run, we create that latch. We pass it here to all of the run and threads. We start all the threads then we deliver on that latch. They all unblock at the same time. Then we wait for them all finish. ]

[Okay. Now we have to write our property that uses this new thread runner. We generate two op-sequences A and B. You can generate more but start with two. We're going to combine them into one sequence and we run our HashMap with that op-sequence. We create a database. Do thread run with ops A and ops B. And then we check if they're equivalent. ]

[Okay. This won't work okay? We need a few more things. We've got the same problem again. Where now we're independently generating two op-sequences and there's no key collisions between them. So we'll never have a store in this thread and a delete in this thread of the same key right? ]

[So we need to solve the same problem again which is really easy. So we'll make a function that will generate n-sequences for us. We're going to generate that set of keys. That solar system of possible keys. Then we make a tuple of the gen-op* where we're passing in the same keys to all of them.]

[So now we use that gen-op-sequences to we'd be structure it into two variables. And now we run it and we have two collisions between threads.]
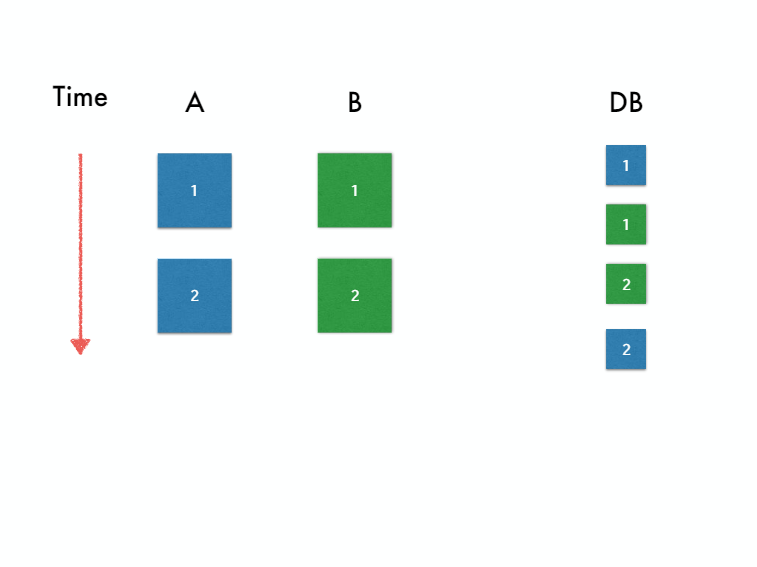
[Okay. The next problem with this it won't work yet. I need to explain graphically so we have these two threads. And let's say that they're just running two operations each. We're sending messages to the database so they're getting queued up in a certain order. They're received at the database in a certain order. What order they received? We don't know. Could be that all of A is come before all B. Could also be that B's happen for A or this one or this one.]
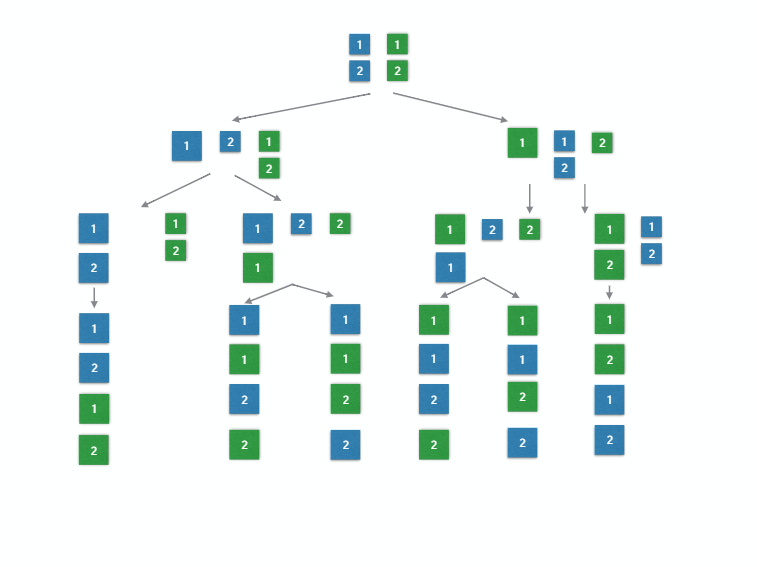
[Turns out that they're six and it's like a tree. So if you choose at any point, A is going to happen next or B is going to happen next. You can left and right. Make this binary tree and there are six possible interleavings of these things. And you can't know what interleaving happens or you can't control which one will happen because that's the nature of thread on the JVM.]
[So the best we can do is say that. Well, we know one of these happened. And so is the plus is what we got. Equivalent to one of these. Any of them. We don't know which one. So we're just going to say as long as it is equivalent to something that could have happened we're good.]

[This generates all possible interleavings. I'm not going to go over the code but it's basically doing that tree building out the whole tree. ]

[Okay. So instead of combining naively the two op-sequences using can cat like I did before. Which only puts A's always before all the B's. This is generating all possible interleavings. We create the database, do the thread run, and then we're going to compare it to all possible ones running on the HashMap and see if at least one is valid. For this, we pass.]

[Okay. So this will work. The problem is very often race conditions are about which interleaving actually did happen. And so you'll run a test and it fails. And you run it again it passes. That's like a heisenbug right?]
[So how do we suss out those heisenbugs? The way that I found that works and that is also in some of papers. John Hughes's is the creator of quick check (the original generative testing system) what they do is they run it ten times. They just run it ten times and they check that it passes every time. If it fails once, then the whole system fails. The whole test fails. And that repetition happens during the shrinkage. So it turns out that in practice, ten is good enough to find the bugs that you need to find.]

[Okay. So now there's this other problem. And if this will work. But when you get it, you might get a failure like this that won't shrink. This is the shrunk version. It's so long. You're like what is it doing? It's doing like a fetch and a delete of something that isn't even in there. ]
[Another dilly wide impact shrink away and you read John Hughes paper and you figured it out it's a timing issue. When you have something like this, it's a timing. It's doing a whole bunch of operations just to get the timing right? Because it takes time to do a fetch. It takes time to do a delete and so thread B just needs to wait a little bit of time. So what do you do? Well, you need to make it so that this can shrink to like a weight. ]
[ So we need a new
generator for a new operation called sleep. And it's a tuple with the
sleep keyword at the beginning. And then it just chooses a number of
milliseconds between one and a hundred. Don't make it too big or your
test will stop.]
So we need a new
generator for a new operation called sleep. And it's a tuple with the
sleep keyword at the beginning. And then it just chooses a number of
milliseconds between one and a hundred. Don't make it too big or your
test will stop.]
[Right. So now we have to add sleep to this gen-op*. So that it's selected as one of the possible operations. And another thing I did was, I reordered them because now we're thinking about shrinking. I reordered them from least destructive to most destructive. One of generator will shrink to the beginning of the collection. So from the right-hand side to the left-hand side. And so now the most destructive thing is going to or the destructive things are going to shrink to less destructive things. I don't know if that really makes a difference but makes me feel better.]

[Okay. So we're going to add thread. The sleep to the DB runner and it's actually going to do a thread sleep easy.]

[Now, in our HashMap runner, sleep doesn't even touch the database so it's not going to modify it. So we just return th HashMap.]
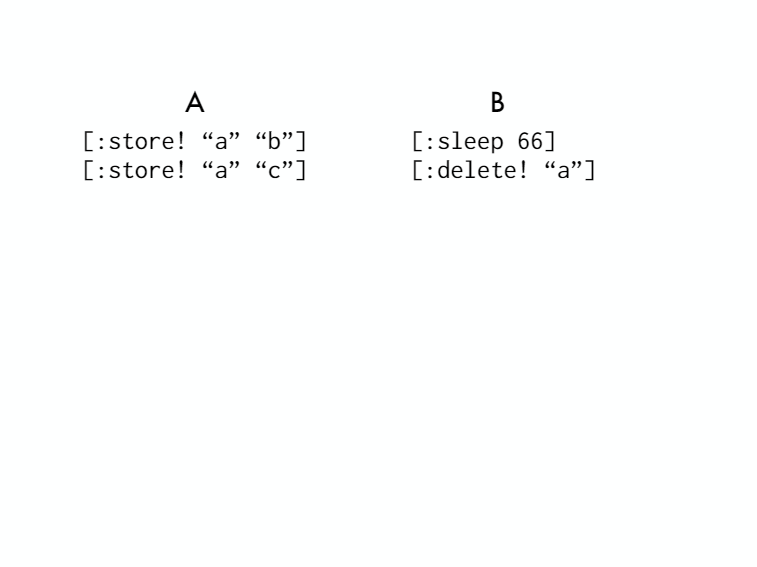
[And now when you run it and it shrinks, this is what you get. It's shrunk to sleep sixty six inches. Will shrink to sleep sixty five. They needed sixty six milliseconds exactly. And what it turns out is this bug was that if you store twice and then delete in another thread, it gets the wrong answer. ]
[So this sleep is enough time to do two stores in thread A. Less than that and it could get interleaved between the two stores or you know happen before the first store. So now we can see the problem right? It's very clear because there's not much noise. ]
[Okay. So I wish I had more time to go into the async stuff. I know the title had a sink in it and I just don't have time. Like, this was already like a lot. But there's two questions remaining. How do you test the system where you don't have an easy model like a HashMap that you can just use like already? And I bet a lot of you have that question. ]
[The other question is what about async stuff? There's no async in here. Notice all the operations were synchronous. I did a delete and I just waited for it to return. And then I could guarantee that it was done when you have multiple systems. Multiple you know, like over a network and they have latency and stuff. You have an eventual consistency model. ]
[Maybe you have caching right? So I sent. I write something gets written to my cache and sometime later it goes to the server. And then gets inked down to the other clients you have. It's a much more complicated system but it turns out that the answer to both of those is the same. Which is to develop a richer model and it's actually not that hard.]
[There's papers about it. It's this model has a still a very small description and I would love afterwards to sit down with some pen and paper and sketch it out for you. Please do that. But right here, what I want to show is the left. We have 25 tests that are written in regular example based testing style. And each test the two operations. And then some make some assertion. And this is all the code we developed in this talk right? Until now.]
[So not only are we like way less code, but we've also modeled a much more complete notion of what the system is supposed to do. We've captured its behavior and we can generate as many tests as we want. We can run this over night. We can have it running in our CI server for hours like all the time basically. We'll really change them like the model of paying for CI servers right? Because right now, they're relying on us to write really small short tests that take like seconds to run.]
[And now we were saying well we can generate tests all all day long. Interesting!]
[There was a talk at Clojure Conj of 2015, where Benjamin Pierce talks about doing this for dropbox. So it's good for existing systems and even black box systems where you don't even have control over what it's doing or any introspection into how it's working. So thank you very much.]